blog
Мы решили поделиться переводом статьи об использовании Prometheus и Grafana
Автор — Louis DeLosSantos
Оригинал статьи на английском https://medium.com/vimeo-engineering-blog/graphing-systems-metrics-with-netdata-prometheus-and-grafana-29ba9ec6bc98
В этой статье я расскажу вам об основных принципах совместного использования Netdata, Prometheus и Grafana для мониторинга ваших серверов приложений. В этой статье на вашей локальной рабочей станции мы будем использовать Docker. Мы будем работать с Docker специальным образом, запуская контейнеры, выполняющие «/bin/bash», и прикрепляя к ним TTY. Я использую Docker здесь чисто в академических целях и не пропагандирую запускать netdata в контейнере. Я выбираю этот метод, чтобы его могли попробовать пользователи, не имеющие облачных учетных записей или доступа к виртуальным машинам, а также по причине быстроты развертывания.
Почему netdata, Prometheus и Grafana
Некоторое время назад коллега познакомил меня с netdata. Мы пытались устранить неполадки в коде python, в котором, как нам казалось, были узкие места. Меня сразу впечатлило количество метрик, предоставляемых netdata. Я быстро добавил netdata к моему набору инструментов, используемых для поиска проблем с производительностью систем.
Позже я познакомился с Prometheus. Prometheus — это приложение для мониторинга, которое переворачивает с ног на голову обычную архитектуру, и получает свои метрики путем опроса REST endpoints. Такое изменение в архитектуре значительно упрощает и сокращает время до начала мониторинга ваших приложений. По сравнению с современными решениями в области мониторинга время, затрачиваемое на проектирование инфраструктуры, значительно сокращается. Запуск одного сервера Prometheus для каждого приложения становится возможным с помощью Grafana.
Grafana уже давно является широко используемым инструментом визуализации. Он потрясающий. Любой, кто его использовал, знает, что он потрясающий. Мы можем указать Grafana в Prometheus и использовать Prometheus в качестве источника данных.
Все это вместе обеспечивает довольно простую общую архитектуру мониторинга: установить netdata на серверах приложений, указать Prometheus в netdata, а затем указать Grafana в Prometheus.
Чтобы сделать это руководство более простым, в этом стеке я исключил такой компонент как импорт, а именно обнаружение сервиса. Я лично предпочитаю использовать Consul. Prometheus может подключаться к Consul и автоматически считывать новые хосты, которые зарегистрировали в Consul клиента netdata.
В конце этого руководства вы поймете, как все эти технологии сочетаются друг с другом и образуют современный стек мониторинга. Этот стек предоставит вам возможность отслеживать производительность ваших приложений и систем.
Начало работы — netdata и контейнеры
Для начала мы создадим контейнер, на который будем устанавливать netdata. Нам нужно запустить контейнер, переслать нужный порт, который будет слушать netdata, и прикрепить TTY, чтобы мы могли взаимодействовать с оболочкой bash на контейнере. Но прежде чем мы это сделаем, нам нужно, чтобы работало разрешение имен между двумя контейнерами. Для этого мы создадим пользовательскую сеть и подключим оба контейнера к этой сети. Первая команда, которую нужно выполнить, показана ниже.
docker network create — driver bridge netdata-tutorial
После того, как мы создали пользовательскую сеть, запустим наш контейнер, на который мы будем устанавливать netdata, и укажем эту сеть.
docker run -it — name netdata — hostname netdata — network=netdata-tutorial -p 19999:19999 centos:latest ‘/bin/bash’
Данная команда создает интерактивный сеанс TTY (-it), присваивает контейнеру имя хоста и имя для демона Docker (так чтобы вы знали, какой контейнер чем является при работе в оболочках, а Docker при разрешении имен установит соответствие имени хоста и этого контейнера), перенаправляет локальный порт 19999 в порт контейнера 19999 (-p 19999: 19999), устанавливает команду для запуска (/bin/bash), а затем выбирает базовые образы (base images) контейнера (centos: latest). После выполнения этой команды вы окажетесь внутри оболочки контейнера.
Внутри оболочки мы можем установить netdata. Ничего не может быть проще. Если вы перейдете по ссылке, там разработчики netdata дают нам несколько «однострочников» для установки netdata. У меня до сих пор не было никаких проблем с этими однострочниками и сценариями загрузки (если вы столкнулись с чем-либо подобным, сделайте комментарий ниже!). Выполните в своем контейнере следующую команду.
bash <(curl -Ss https://my-netdata.io/kickstart.sh) — dont-wait
После завершения установки вы можете получить доступ к панели управления netdata на http://localhost:19999/ (замените localhost, если вы делаете это на виртуальной машине или если контейнер Docker размещен на машине не в вашей локальной системе). Если вы впервые используете netdata, я предлагаю вам попробовать с ним поработать. Этот инструмент значительно сократил время, которое я потратил, копаясь в /proc и вычисляя собственные метрики. Поупражняйтесь с ним.
Далее, я хочу обратить ваше внимание на конкретный endpoint. Перейдите в вашем браузере на http://localhost:19999/api/v1/allmetrics?format=prometheus&help=yes
Этот endpoint публикует все метрики в формате, который понимает Prometheus. Давайте посмотрим на одну из этих метрик.
netdata_system_cpu_percentage_average{chart=”system.cpu”,family=”cpu”,dimension=”system”} 0.0831255 1501271696000
Эта метрика представляет несколько вещей, о которых я расскажу подробнее в разделе о Prometheus. Сейчас достаточно понять, что эта метрика: netdata_system_cpu_percentage_average имеет несколько ярлыков: [chart, family, dimension]. Это соответствует первой диаграмме процессора, которую вы видите на панели управления netdata.
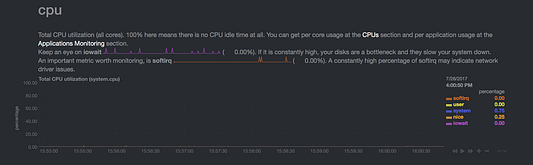
Эта диаграмма (chart) называется «system.cpu», семейство (family) — «cpu», а наблюдаемый диапазон (dimension) – «system». Вы можете начать рисовать таким образом связи между диаграммами в netdata и форматом метрик Prometheus.
Устанавливаем Prometheus
В целях демонстрации будем устанавливать Prometheus в контейнер. Хотя у Prometheus есть официальный контейнер, я хотел бы пройти весь процесс установки и установить его в новый контейнер. Это позволит любому читателю применить данное руководство на виртуальной машине или сервере любого типа.
Давайте создадим еще один контейнер таким же образом, как и контейнер для netdata в предыдущем разделе.
docker run -it — name prometheus — hostname prometheus — network=netdata-tutorial -p 9090:9090 centos:latest ‘/bin/bash’
Вы снова попадете в оболочку. Там сразу установите ваш любимый редактор, поскольку далее в этом руководстве мы будем редактировать файлы.
yum install vim -y
Prometheus предоставляет tar-архив из последних стабильных версий, поэтому давайте загрузим его самую последнюю версию и установим ее в ваш контейнер.
curl -L ‘https://github.com/prometheus/prometheus/releases/download/v1.7.1/prometheus-1.7.1.linux-amd64.tar.gz’ -o /tmp/prometheus.tar.gz
mkdir /opt/prometheus
tar -xf /tmp/prometheus.tar.gz -C /opt/prometheus/ — strip-components 1
В результате Prometheus будет установлен в контейнер. Давайте проверим, можем ли мы запустить Prometheus и подключиться к его веб-интерфейсу. Это будет выглядеть примерно так:
[root@prometheus prometheus]# /opt/prometheus/prometheus INFO[0000] Starting prometheus (version=1.7.1, branch=master, revision=3afb3fffa3a29c3de865e1172fb740442e9d0133) source=”main.go:88″ INFO[0000] Build context (go=go1.8.3, user=root@0aa1b7fc430d, date=20170612–11:44:05) source=”main.go:89″ INFO[0000] Host details (Linux 4.9.36-moby #1 SMP Wed Jul 12 15:29:07 UTC 2017 x86_64 prometheus (none)) source=”main.go:90″ INFO[0000] Loading configuration file prometheus.yml source=”main.go:252″ INFO[0000] Loading series map and head chunks… source=”storage.go:428″ INFO[0000] 0 series loaded. source=”storage.go:439″ INFO[0000] Starting target manager… source=”targetmanager.go:63″ INFO[0000] Listening on :9090 source=”web.go:259″
Теперь попробуйте перейти на http://localhost:9090/. Вы попадете на домашнюю страницу Prometheus. Пора нам поговорить о модели данных, которую использует Prometheus. Как указано, в метриках Prometheus есть два ключевых элемента — метрика и ее ярлыки. Ярлыки позволяют детализировать метрики. Поясним это на нашем предыдущем примере.
netdata_system_cpu_percentage_average{chart=”system.cpu”,family=”cpu”,dimension=”system”} 0.0831255 1501271696000
Здесь «netdata_system_cpu_percentage_average» — это метрика, а «chart», «family» и «dimension» — ярлыки. Два значения в конце строки представляют собой фактическое значение метрики для метрики данного типа (измеритель, счетчик и т.п.). С помощью этой информации мы можем начинать визуализировать метрики системы, но сначала нужно, чтобы Prometheus начал опрашивать статистику netdata.
Рассмотрим теперь конфигурацию Prometheus. Prometheus получает свою конфигурацию из файла, расположенного — в нашем примере — в /opt/prometheus/prometheus.yml. Я не буду тратить много времени на рассмотрение значений параметров конфигурации. Мы добавим новое задание «job» в «scrape_configs». Давайте сделаем вот такой раздел «scrape_configs» (мы можем использовать dns-имя netdata, так как мы ранее создали с помощью Docker специальную пользовательскую сеть).
scrape_configs: # The job name is added as a label `job=` to any timeseries scraped from this config. — job_name: ‘prometheus’ # metrics_path defaults to ‘/metrics’ # scheme defaults to ‘http’. static_configs: — targets: [‘localhost:9090’] — job_name: ‘netdata’ metrics_path: /api/v1/allmetrics params: format: [ prometheus ] static_configs: — targets: [‘netdata:19999’]
Давайте снова запустим Prometheus, выполнив /opt/prometheus/prometheus. Если мы теперь перейдем в Prometheus на «http://localhost:9090/targets», мы увидим, что наша цель успешно считывается. Если мы вернемся на домашнюю страницу Prometheus и начнем вводить «netdata_», Prometheus будет автоматически заполнять метрики, которые он теперь считывает.
Переходим к визуализации
Давайте теперь изучим, как мы можем визуализировать некоторые метрики. Вернемся в наш контейнер netdata и заставим центральный процессор выполнять некие операции в бесконечном цикле. В оболочке задайте следующее:
[root@netdata /]# while true; do echo “HOT HOT HOT CPU”; done
На нашем графике работы ЦП в netdata будет отображаться некоторая активность. Давайте представим ее в Prometheus. Чтобы сделать это, давайте оставим нашу страницу метрик (для справки) открытой: http://localhost:19999/api/v1/allmetrics?format=prometheus&help=yes
Мы собираемся графически отображать данные диаграммы ЦП, поэтому найдем «system.cpu» на указанной выше странице метрик. Мы находим раздел метрик с первыми комментариями:
# COMMENT homogeneus chart “system.cpu”, context “system.cpu”, family “cpu”, units “percentage”
ниже следуют метрики.
Хорошее начало. Теперь давайте перейдем к конкретной метрике, которую мы хотели бы визуализировать.
# COMMENT netdata_system_cpu_percentage_average: dimension “system”, value is percentage, gauge, dt 1501275951 to 1501275951 inclusive
netdata_system_cpu_percentage_average{chart=”system.cpu”,family=”cpu”,dimension=”system”} 0.0000000 1501275951000
Здесь мы узнаем, что имя метрики, которая нам нужна — «netdata_system_cpu_percentage_average». Задайте его в Prometheus и давайте посмотрим, что мы получим. Мы должны увидеть что-то вроде этого (я отключил бесконечный цикл):
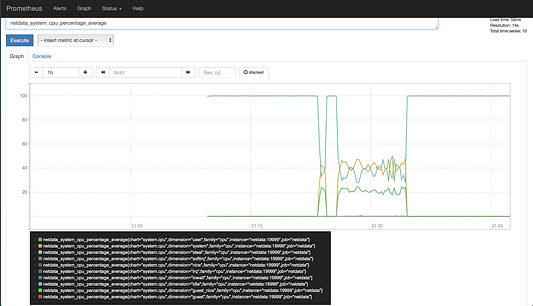
Мы приблизились к тому, что нам нужно. Заметьте также, что Prometheus отметит для нас ярлык «instance», соответствующий нашему статически определенному заданию в конфигурационном файле. Это позволяет нам адаптировать наши запросы к конкретным экземплярам. Теперь нам нужно выделить диапазон («dimension»), к которой будет применяться наш запрос. Для этого давайте немного уточним запрос. Поместите в текстовое поле нашего запроса следующее.
netdata_system_cpu_percentage_average{dimension=”system”}
Теперь вы должны получить в результате следующий график.
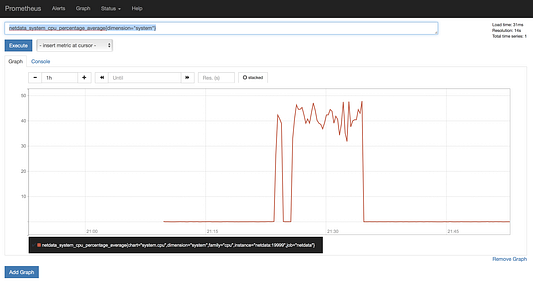
Удивительно — это именно то, что нам нужно. Если вы еще не поняли — мы можем эмулировать целые диаграммы из netdata, используя диапазон (dimension) «chart». Если хотите, вы можете объединить диапазон «chart» и «instance» для создания диаграмм для каждого экземпляра. Давайте попробуем:
netdata_system_cpu_percentage_average{chart=”system.cpu”, instance=”netdata:19999″}
Это основы использования Prometheus для выполнения запросов к netdata. Здесь я бы посоветовал всем прочесть эту страницу. Ключевой момент здесь, что netdata может экспортировать метрики из своей внутренней БД или же может отправлять метрики «как собраны» («as-collected»), указав параметр url «source=as-collected», например: http://localhost:19999/api/v1/allmetrics?format=prometheus&help=yes&types=yes&source=as-collected
Если вы решите использовать второй метод, для получения полезных метрик вам нужно будет использовать набор функций Prometheus, поскольку в этом случае вы будете иметь дело с «сырыми» (raw) счетчиками из системы.
Например, вам нужно будет применить к счетчику функцию irate (), чтобы получить скорость этой метрики в секунду. Если ваши потребности в визуализации удовлетворяются с помощью метрик, получаемых из внутренней базы данных netdata (не задан параметр source= url), то используйте этот вариант. Если столкнетесь с ограничениями, рассмотрите возможность перезаписи своих запросов с использованием «сырых» данных и функций Prometheus для получения нужной диаграммы.
Устанавливаем Grafana и рисуем, сколько нашей душе угодно
Наконец мы добрались и до Grafana! На мой взгляд, это самая легкая часть. В этот раз мы в действительности запустим официальный контейнер Grafana Docker, поскольку вся конфигурация, которую нам нужно создать, задается через графический интерфейс. Давайте выполним следующую команду:
docker run -i -p 3000:3000 — network=netdata-tutorial grafana/grafana
Grafana запустится на «http://localhost:3000/». Перейдем туда и войдем с помощью учетных данных Admin: Admin.
Первое, что мы сделаем — это добавим источник данных, кликнув «Add data source». Давайте получим то, что показано на скриншоте ниже:
Визуализируем
Закончив с этим, давайте визуализировать! Создайте новую панель инструментов, щелкнув иконку в верхнем левом углу Grafana, и создайте новый график в этой панели. Заполните запрос, как мы делали выше, и сохраните.
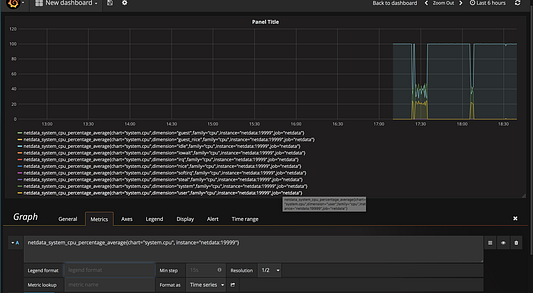
Что в итоге
Итак, у вас есть полный стек для мониторинга систем, который очень легко развернуть. Здесь я хотел бы предложить вам поисследовать, как Prometheus и механизм обнаружения сервисов, такой как Consul, могут хорошо работать вместе. Мои сегодняшние продуктивные системы автоматически регистрируют сервисы netdata в Consul, и Prometheus автоматически начинает их считывать. Это настолько потрясающе и функционально! Как только вы наладили весь механизм, вам больше не нужно будет думать о системе мониторинга – до тех пор, пока Prometheus справляется с масштабом вашей системы. Если наступит момент, когда он не сможет с ним справляться, в документации Prometheus есть варианты решения этой проблемы.
Надеюсь, это было полезно. Если у вас есть другие вопросы или свои собственные интересные наблюдения, не стесняйтесь писать их в комментариях ниже. Счастливого мониторинга!